
本文紧跟大模型评测行业前沿。
首先,通过调研2023-2025年的文本大模型评测领域的实践,抽象出评测核心三要素:维度、指标与评测集;
其次,结合货运行业知识,设计货拉拉大模型的评测框架;
最终,基于公司实际场景与数据沉淀,形成了货拉拉特色的评测实践,并加速AI应用在公司的落地,目前已复用到邀约、客服等多个场景和业务线。
一、背景概述
- 文本大模型评测是什么
文本大模型评测是通过设计合理的评价维度、数据集与指标,对模型的语言理解、生成、安全等能力进行系统、全面、科学的评估,以此驱动模型迭代优化,满足实际业务需求。
➡️就像为文本大模型量身定制的 “考试体系”,既包含基础能力的 “随堂测验”,也涵盖实际应用的 “实战考核”,最终助力模型通过“考核”以适配业务需求。
- 为什么它那么重要
- 技术闭环保障:构建“数据准备—>模型设计与训练—->能力评测—>上线及运营”的完整技术闭环
- 能力说明书:明确模型的功能边界与适用场景,解答”能做什么/不能做什么”的核心问题
“AI教母”李飞飞名言:大模型解决的是【世界从哪里来】的问题,而大模型评测解决的是【进步怎么被衡量】的问题

大模型炼丹应用的生命周期,及评测扮演的角色
- 那该如何做呢?
我们调研近3年国内外文本评测方向的成果。
调研目的:提炼核心焦点,构建货拉拉大模型评测的理论框架。最终结合公司场景知识和数据,形成了我们自己的评测实践,并抽象出货运行业特色的评测能力、评测框架,加速AI应用在公司的落地。
调研成果:学术与工业界的研究核心均围绕两个根本性问题展开: “评测什么”与“怎么评测”。
- 评测什么:主要是大模型的通用能力(2023年,摸索智商边界,类似9年义务教育)、领域能力(2024年,培养专业的技能,类似于大学分专业教育)、场景能力(2025年,主攻重商业价值。公司的岗位培训,如客服、营销、数据等)。
- 怎么评测:评测框架,模型能力应该拆分成哪些维度考察,需要什么量化指标去度量,用什么样的方式进行主客观打分以及用什么样的数据科学方法得出结论?
二、评测什么
根据评测目标的差异化和覆盖完整性,我们参考国标、顶尖高校和头部公司(详见附录),把评测分成通用、领域、业务三大场景能力
(一)通用能力
- 定义与特点定位
模型的入门门槛,重点考察大模型的基础能力
- 定义:指满足不同技术领域、不同用户群体共性需求,具备跨场景复用价值的评测情境,核心覆盖大模型的基础能力验证,不依赖特定行业知识或专属数据。
- 特点定位:该场景是大模型评测的 “基础门槛”,也是后续细分场景评测的前提。
- 评估流程–以MMLU Pro为例

MMLU Pro的评估流程是通过自动打分和人工打分的多指标评估,最终输出量化表格与公开排行榜的完整闭环流程
(二)领域能力
定义与特点定位
- 定义:行业的垂直深化,考察大模型的垂直领域适配性,比如:医疗、金融、教育、法律等行业
- 特点定位:面向垂直行业,需结合行业知识、合规要求的评测情境,分类依据是 “行业数据特性与核心需求差异” ;解决 “通用模型在行业落地中适配性” 问题,旨在避免** “通用场景得分高但行业实用性低”** 的矛盾。
评估流程
与通用的方式基本一致,差异点主要在于数据集构造、评测维度、指标会有些不同。
以医疗领域的CliMedBench为例,评测集有33,735 个中文医学基准,涵盖 14 个专家指导的核心临床场景。从7 个关键维度评估 LLMs 的医学能力,模拟真实医疗实践,测试模型在医学知识、推理能力和临床适用性方面的综合能力。
(三)场景能力
定义与特点定位
- 定义:大模型落地验证,重点关注大模型落地实用性和安全性如何,涉及到客服、营销、数据分析、办公等企业经营的方方面面。
- 特点定位:面临的具体使用情境,需结合用户交互流程与业务目标,核心特征是 “任务闭环化、交互真实化”,更关注 “端到端解决问题的能力”,该场景是连接 “模型能力” 与 “用户价值” 的关键纽带。
评估流程
流程可复用领域的评测流程,差异点在于业务目标与场景数字人的评价标准,数据更加个性化,以及有明确的业务指标。比如转化率、一解率等。
安全能力评估–以M3-SafetyBench为例,该基准首次系统性地构建了“内容安全-功能安全”双层评估架构,覆盖通用领域与教育垂直领域,整合了开放式生成、选择题、红队攻击等多种测评方式,并构建了超过17万条高质量测试数据
三、评测方案
“评测考察点、用什么数据评、标准衡量的标准是什么”的具体实现
明确了“评测什么”的问题之后,接下来就是看如何做评测?
我们对国家标准化管理委员会、上海人工智能实验室、以及产业界的头部玩家进行了跟踪。总结归纳出两个核心方面:一、术的层面,保障全面性:需要哪些指标、哪些维度、什么样的数据。二、器的层面,保障科学性:用什么工具,什么资源进行评测。
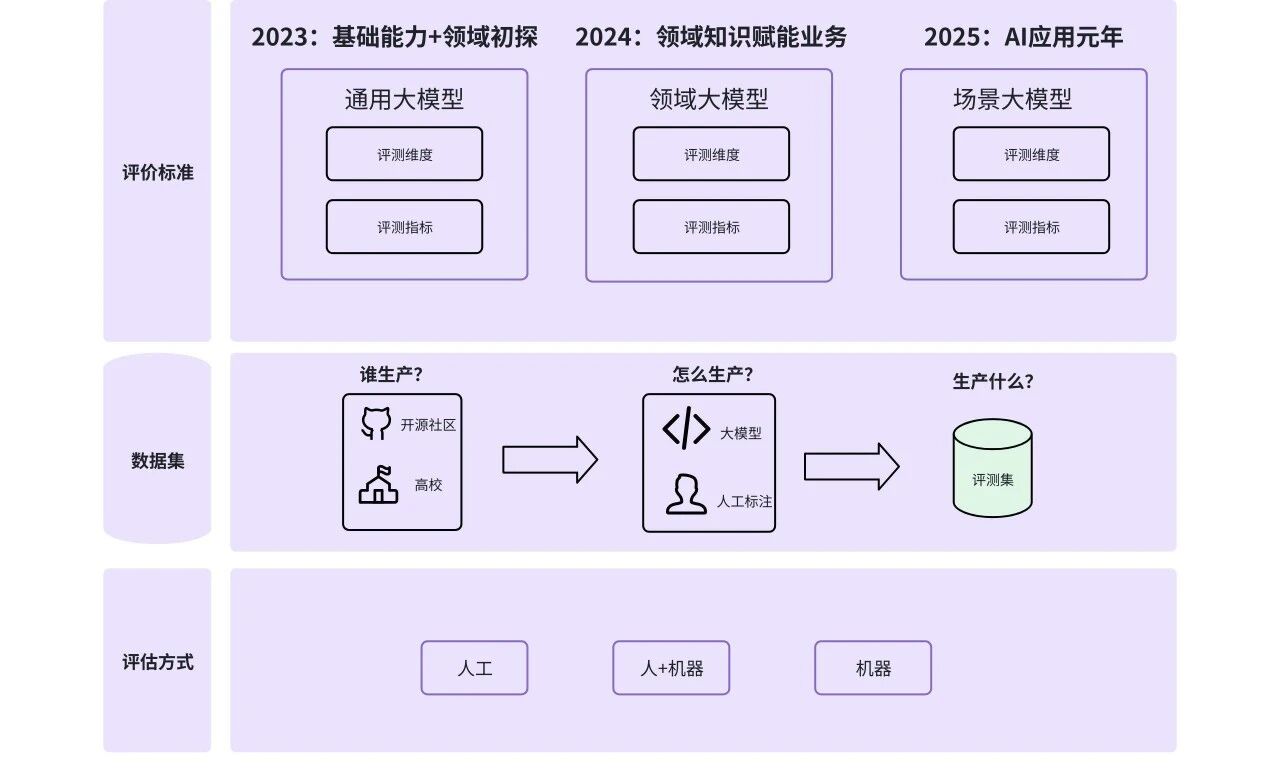
评测方案的全景图,以及发展脉络
(一)评测维度 & 指标(考试大纲)
对比24年,25年国内外框架的指标体系,更精准贴合场景应用中模型能力评估的需求,且注重划分人/机指标。
需求导向:评测对传统指标的依赖显著减小,而是制定出有针对性或人工指标,服务于具体任务场景或需求;
安全风控:对比传统范式,新范式已形成更系统科学的安全指标,实现“技术+安全”的综合风控转变;
综合评估:注重自动化评估与人工评估的结合使用,评测结果兼具可量化性与可解释性,综合衡量模型效果。
(二)评测数据(试卷题目)
数据的演变现状和主流趋势是什么?
- 评测基准产生
评测基准由谁构建的?
25年整体向学术引领、应用驱动、协同创新发展:学术机构仍是评测集构建标杆,企业自建则紧贴应用场景,且联合构建与跨界合作成为主流。
- 针对迭代:传统知名评测集在保留任务多样性的基础上,通过对抗性替换与选项扩展等方式实现迭代。
- 需求驱动:传统学术构建基准已难以满足行业应用需求,25年企业自建与开源评测集快速增多。
- 多元协同:25年产学研联合构建成为主流,涌现出一批高质量合作成果,多元化与协同化构建趋势明显。
评测集的示例
| 评测集分类 | 核心用途 | 数据集示例 |
|---|---|---|
| 通用能力评测集 | - 衡量模型的<strong>基础认知能力,比如语言、知识、推理、数学等</strong> | 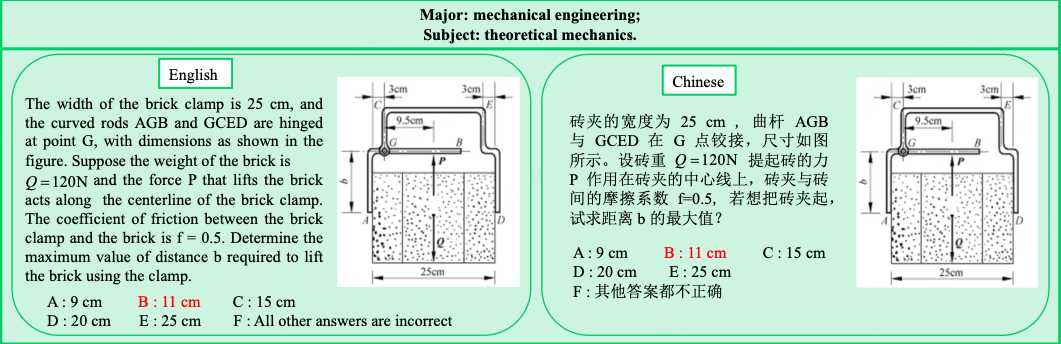 |
| 领域评测集 | - <strong>能力评估</strong>:评估模型在特定专业场景的适配性和应用能力 - <strong>优化建议</strong>:为行业落地(如医疗、法律、工程、金融)提供性能参考 |
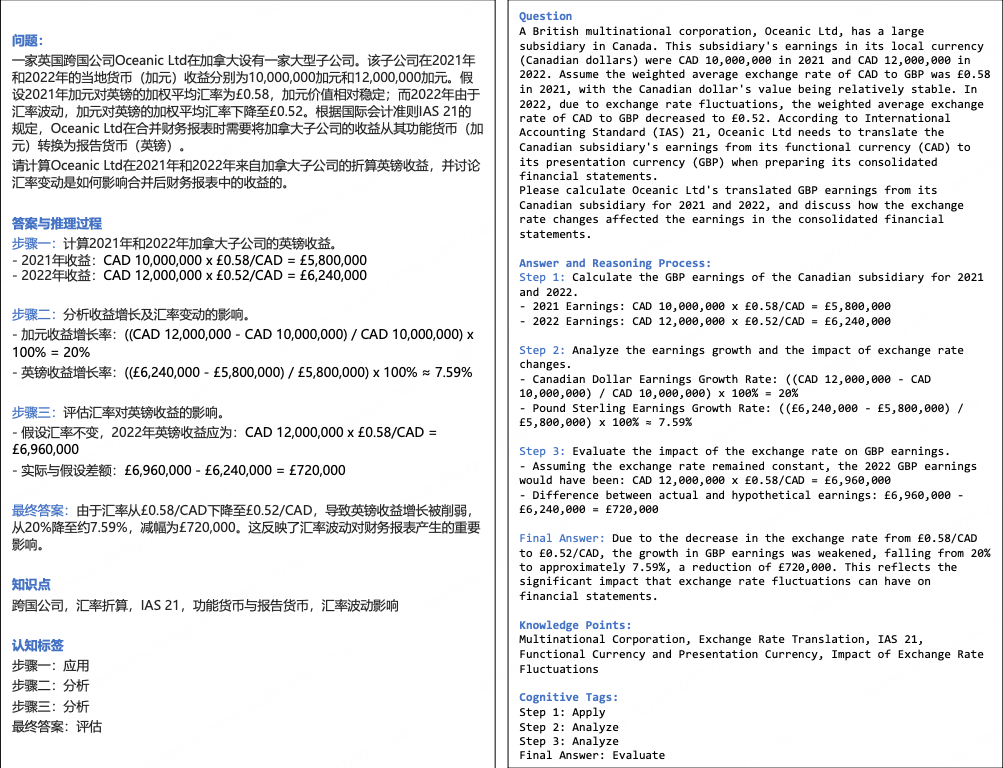 |
| 场景评测集 | - <strong>能力评估</strong>:针对性检测模型的风险隐患、专项功能表现 - <strong>优化迭代</strong>:助力模型优化安全性、可靠性及特定场景适配性 |
 |
- 如何构建评测集?
相比24年,业内评测集构建仍由人工主导,但模型辅助以多种方式深度融入构建流程,发挥可靠提效作用。
人工:领域专家仍是高质量和权威性数据构建的主力
- 人工构建举例:美团 LongCat 团队数学推理评测基准AMO-Bench构建
- 构建流程如下:
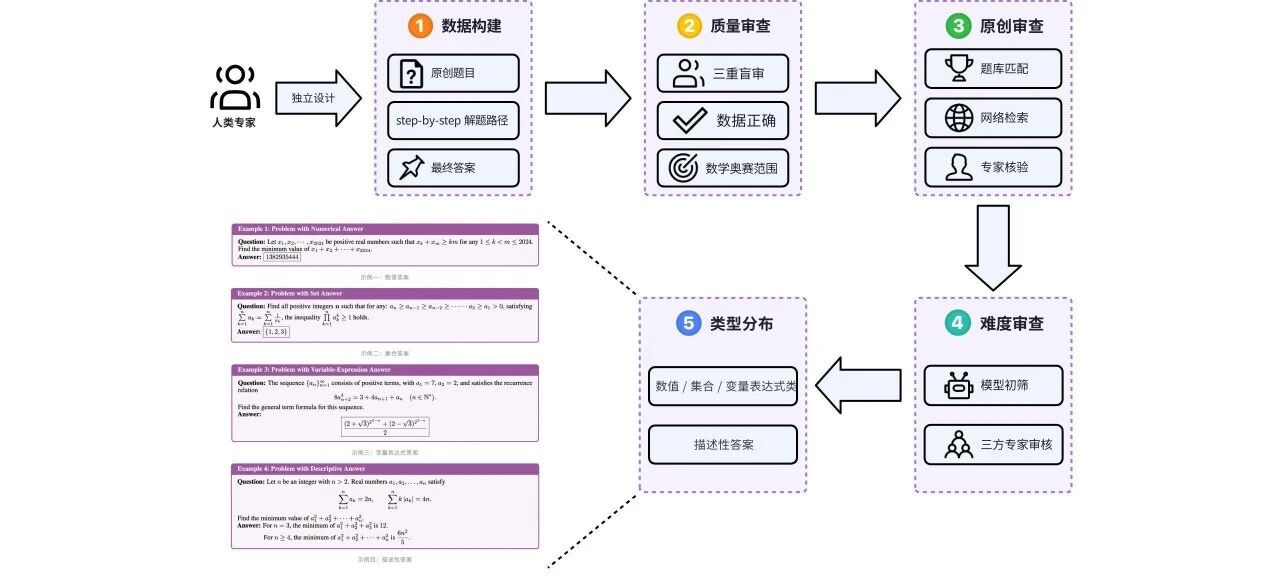
美团LongCat团队的AMO-Bench人工数学推理评测集生产过程
机器:基于规则构建与半自动标注是当前主流构建趋势,协同构建兼顾质量与效率,科学性强。
- 机器构建举例:基于DARG框架构建新评测数据
- DARG框架(Dynamic Evaluation of LLMs via Adaptive Reasoning Graph Evolvement,基于自适应推理图的大模型动态评估框架)原理如下:
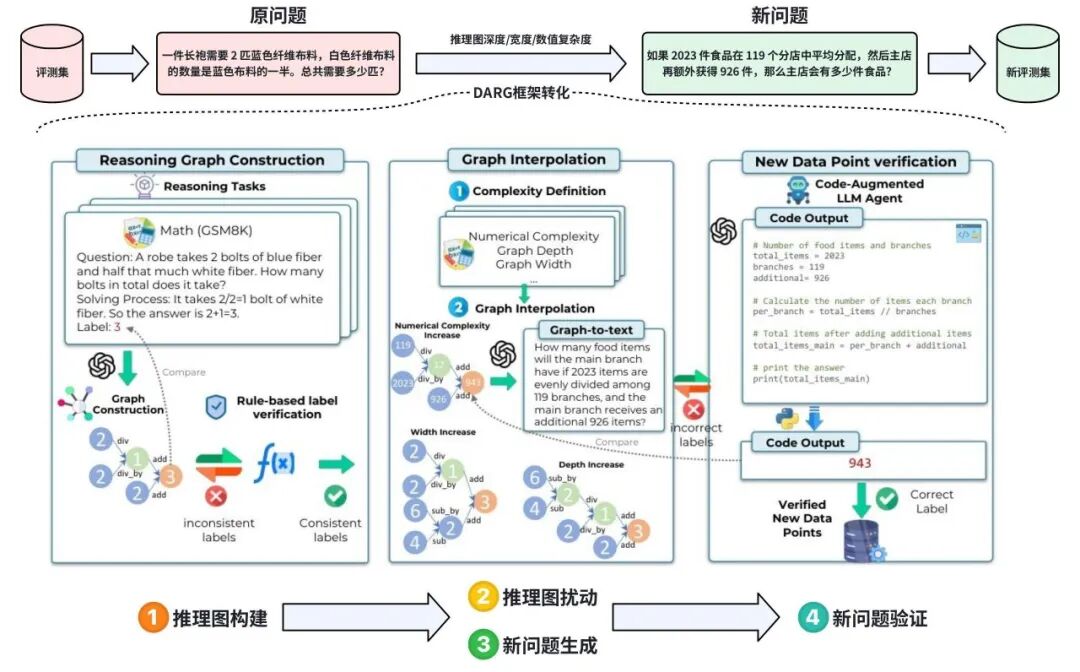
DARG框架:从原评测题出发,经推理图构建、复杂度扰动、新问题生成等动态生成高质量新评测题(图片来源:https://arxiv.org/abs/2406.17271)
(三)评测方式(阅卷)
对比24年调研情况,agent开创新方式;企业评测体系开始构建并落地实践,而人机协同发展趋势明显。
人工
人工评测模式保持稳定,纯人工评测应用热度呈下降趋势;仍以学术机构主导建设,且仅少数机构厂商公布了实践落地情况。
- 工业界公开信息较少,现有已知方法论较一致,HLL建设较好且科学性上更严谨。
- 学术界仍以大模型竞技场为代表。其中LMArena榜单国际认可度极高,25年进行了算法优化和模型阵容扩充。
- 系统性评测(Systematic evaluation)
基于系统化的评测方案,确定评测人员及评测集,经过规范化的人工评估形成最终评测结果。
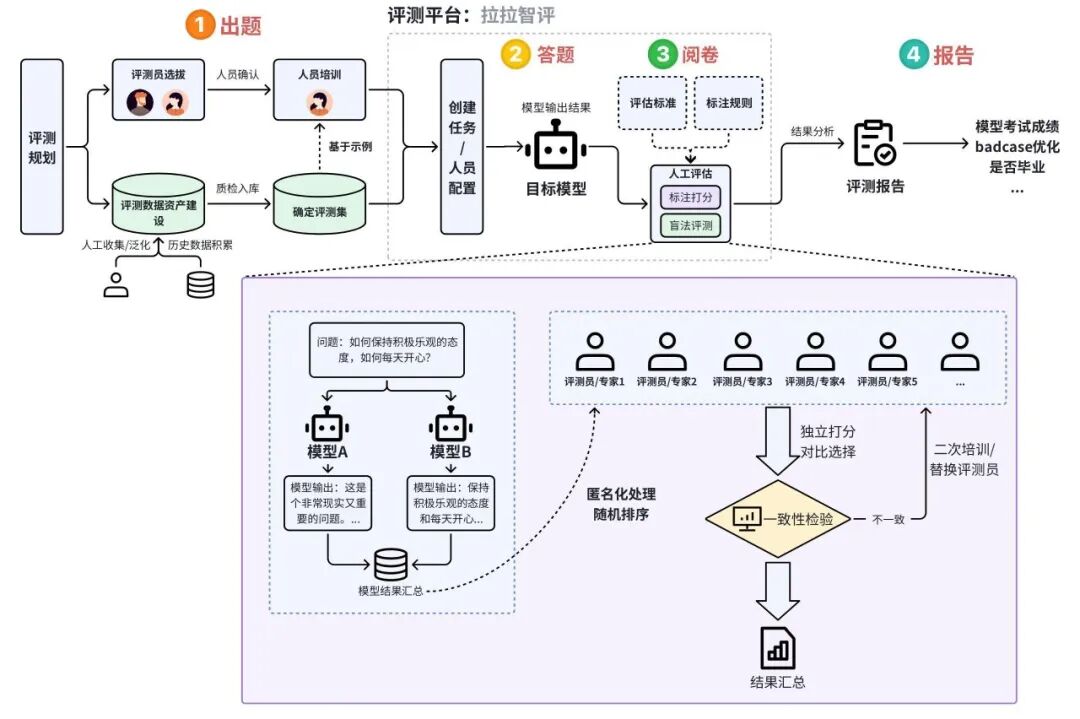
人工评测流程
- 竞技场(Arena)–非正式评测(Casual evaluation)
采用众包人工评估方式,对比同一问题多模型输出结果并进行实时投票,最终依据统计指标动态更新排名榜单。
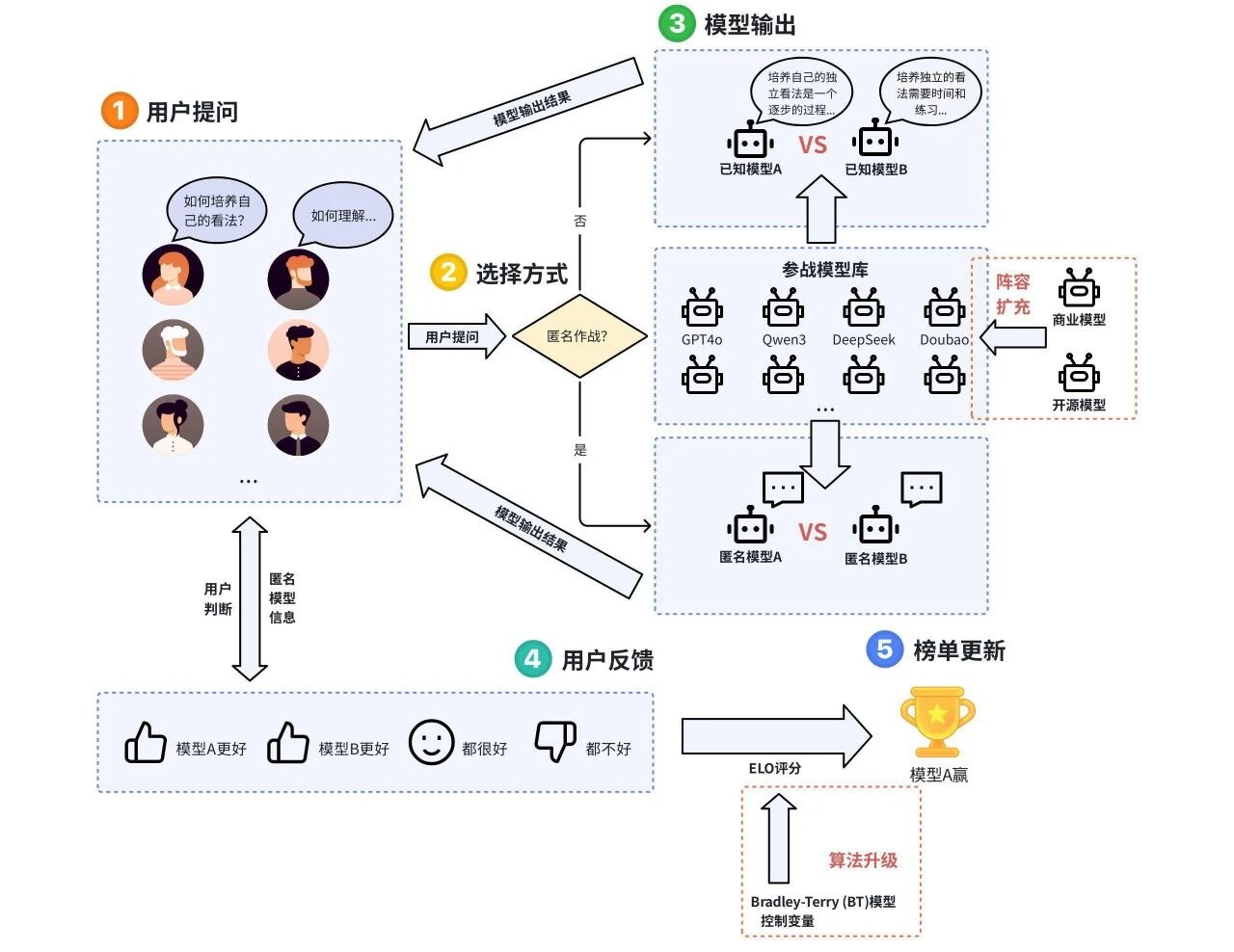
竞技场式评测流程
人机协同
作为当前主流探索方向,人机协同评测通过”人工主导+模型辅助”的混合范式,在保证质量可控的前提下显著提升评测效率。该模式已在头部企业落地实践。
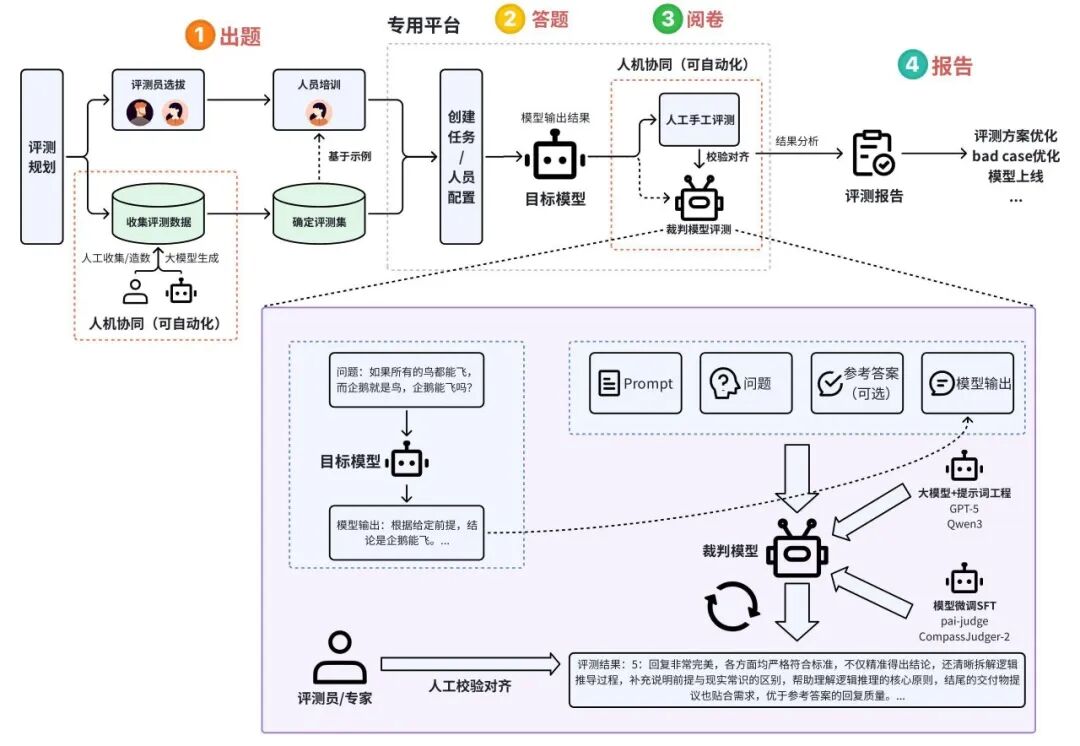
人机协同评测全流程图,模型参与“出题”与“阅卷”阶段,辅助提升评测质量与效率
- 裁判模型(LLM-as-a-Judge)示例:阿里裁判大模型(pai-judge)
可根据不同的任务进行自动化指标选取,并且模型可以替代人工进行效果评价。
工作模式
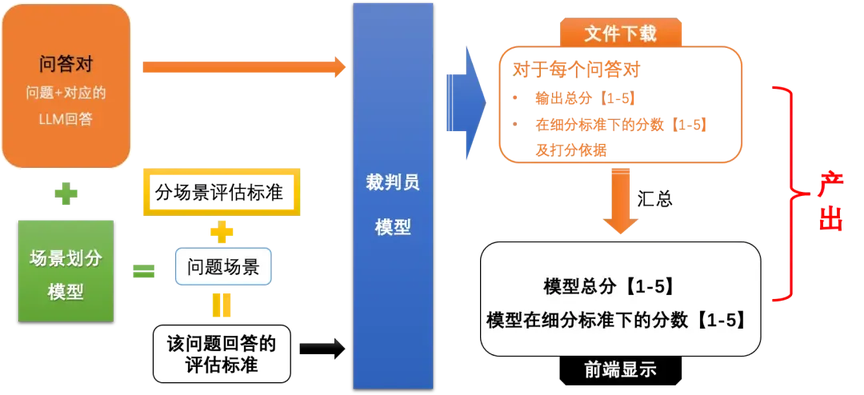
阿里裁判员模型工作模式图
(来源:https://help.aliyun.com/?spm\=a2c4g.11186623.help-sub-nav.d\_logo.293d6954OJrXaq)
机器
- 概念:无需依赖人工标注或打分,通过使用预定义数据集、工具自动地量化大模型性能,且指标可通过算法、工具或预定义规则直接计算的评测方法
根据核心主体,划分为基于基准测试和智能体的两种自动化评测。
- 传统自动化评测–基于基准测试(benchmark)
通过设计合理的测试任务和评价数据集来客观、公正、量化的评估模型的性能,是目前产业界和学术界最为认可的模型能力评估方法。
评测形式:根据模型是否自由输出,分为选择题基准和验证器式基准评测(如数学、编程领域)
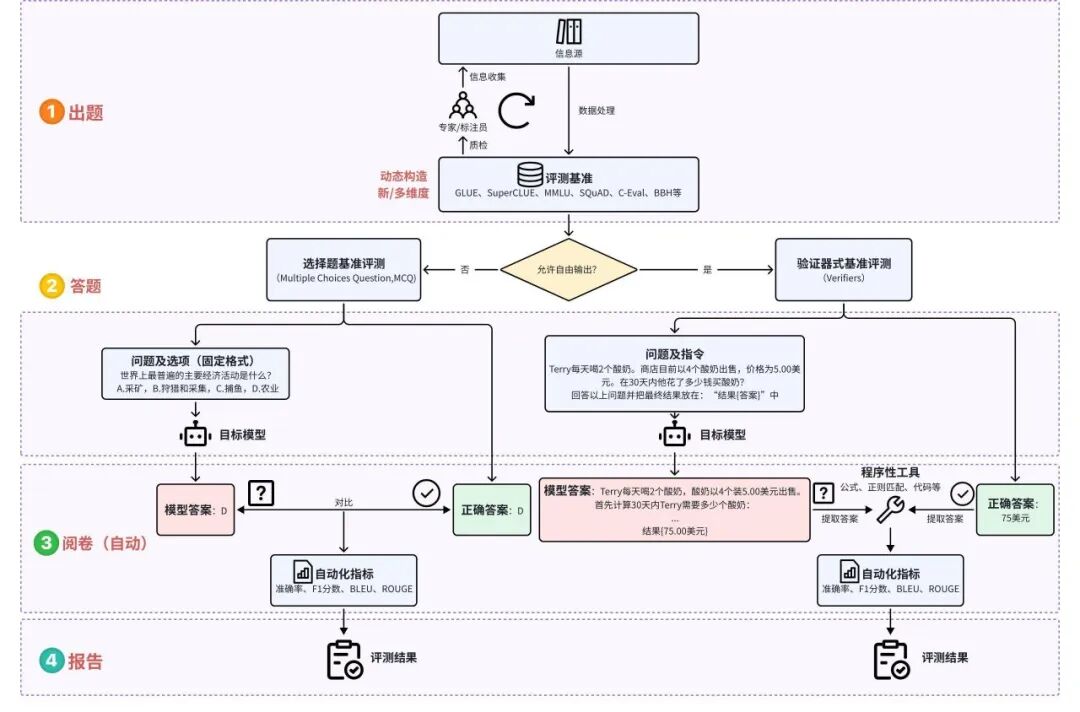
传统自动化评测流程图:模型输出方式不同,问题也分为“固定”与“指令”两种形式
- 新自动化评测–基于智能体(agent)
概念:暂无明确统一定义,以评测引擎为核心,对智能体输出效能进行标准化自动评估的方式。
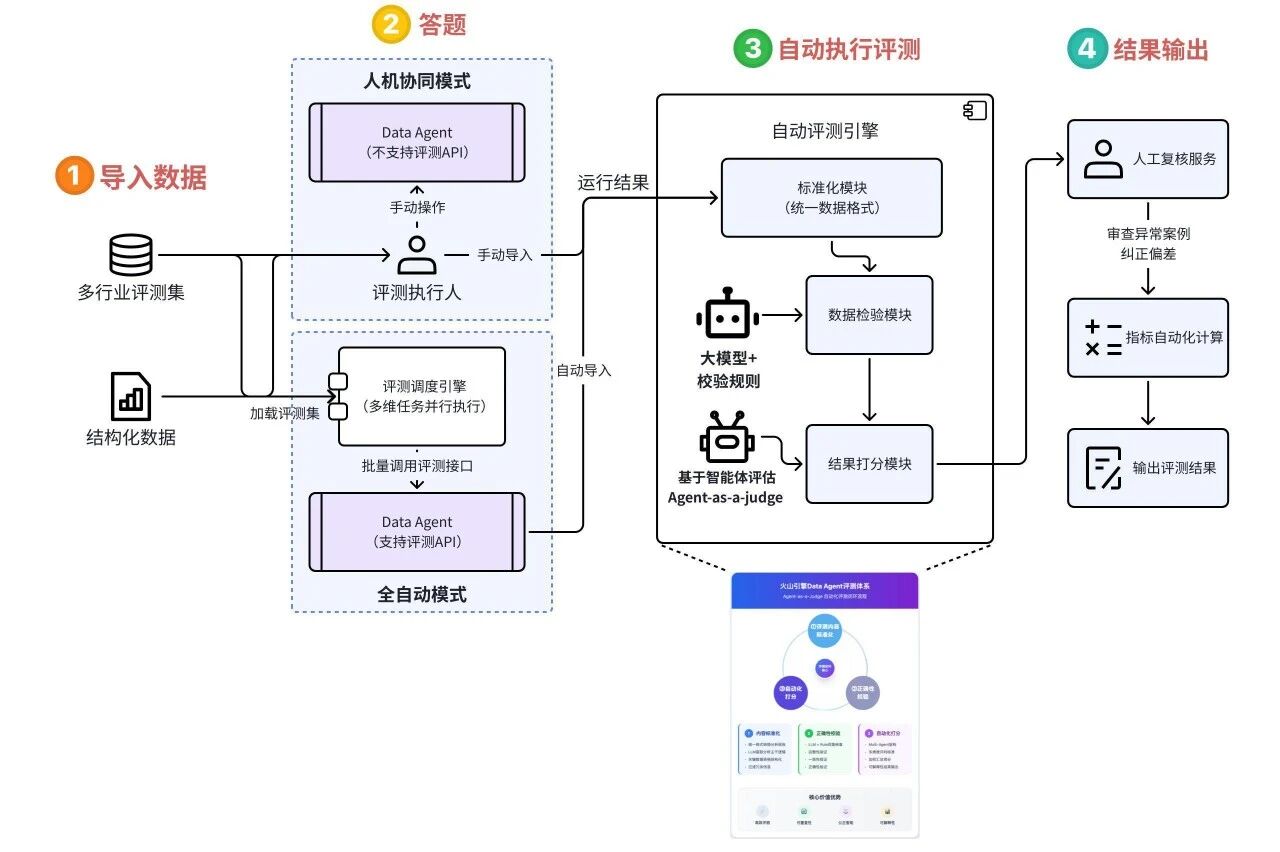
通过多行业/结构化数据输入,经人机协同或全自动(批量调用接口)两种模式答题,再通过自动评测引擎的标准化模块、数据检验模块等模块执行评测,最后经人工复核异常案例、自动计算指标后输出评测结果
(来源:https://mp.weixin.qq.com/s/s2SKbOb8nqqKLVuhb-HwLQ)
小结
| ##### 评测形式 | 优缺点 | ##### 适用场景 |
|---|---|---|
| 人工评测 | - <strong>优点</strong><strong>:</strong> 可靠性最高、接近人类偏好、主观评估的黄金标准- 缺点: 人工成本最高、一致性较差、周期长 |
- 需综合评估、主观性强、语境复杂、长文本等的困难任务 - 价值高、样本量较小,注重用户交互体验的场景 - 缺乏成熟评估指标/维度的场景 |
| 人机协同评测 | - <strong>优点</strong><strong>:</strong> 可靠性较高、人工控制质量、大模型降低成本并提升效率- 缺点: 大模型输出质量需人工严格控制、周期较长,需要一些标准输入 |
- 数据量需求大,纯人工评测成本过高的场景 - 容错率较高,可经人工复核修正的场景 - 已沉淀可标准化的人工经验 |
| 机器 | - <strong>优点</strong><strong>:</strong> 效率高、一致性高、周期短- 缺点: 质量无人把控,科学性得不到保障 |
- 客观性问题/领域 - 传统机器学习领域 - 有客观的度量指标和标准化的问答对。 |
四、货拉拉AI应用评测实践
基于调研的评测行业信息,结合货拉拉实际业务场景特点,已沉淀一套半自动的评测体系,加速AI在邀约、客服、办公等场景的落地应用。
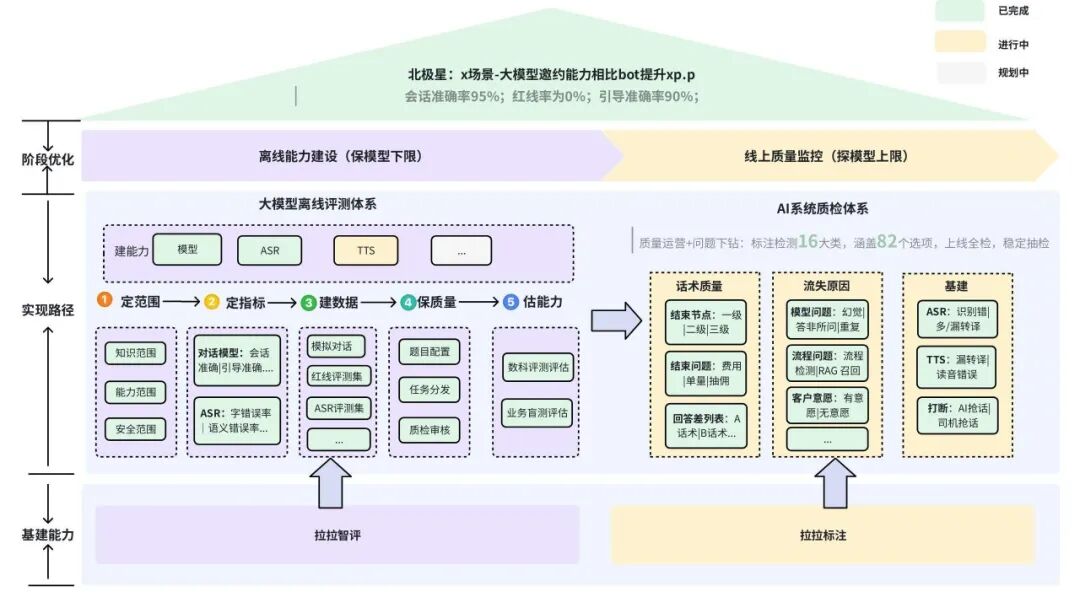
货拉拉x场景半自动评测体系图
四、以某场景为例
(一)评测方案
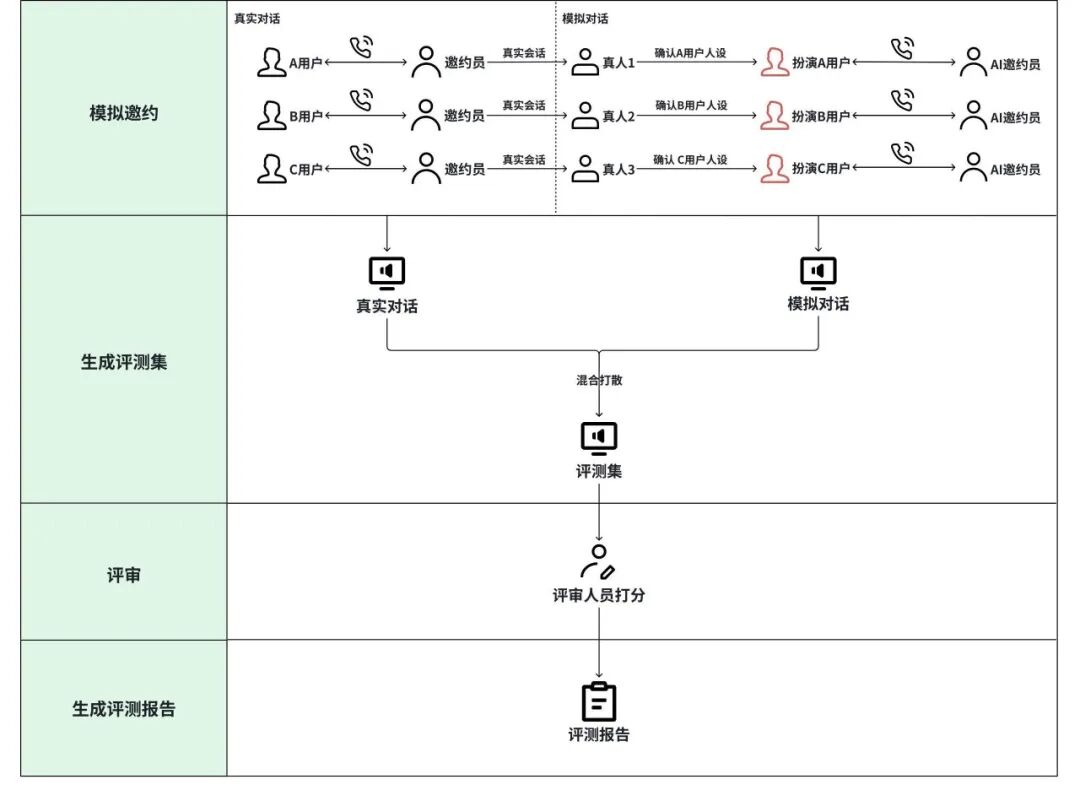
货拉拉x场景评测方案流程图,展示从模拟邀约数据提取数据到生成评测报告的整个对话评测流程
1. 评测集
1.1 评测集生成
评测集构建流程:通过模拟真实用户,确定人设并与AI邀约员对话形成模拟问答集,通过与真实数据混合方式构建最终评测集
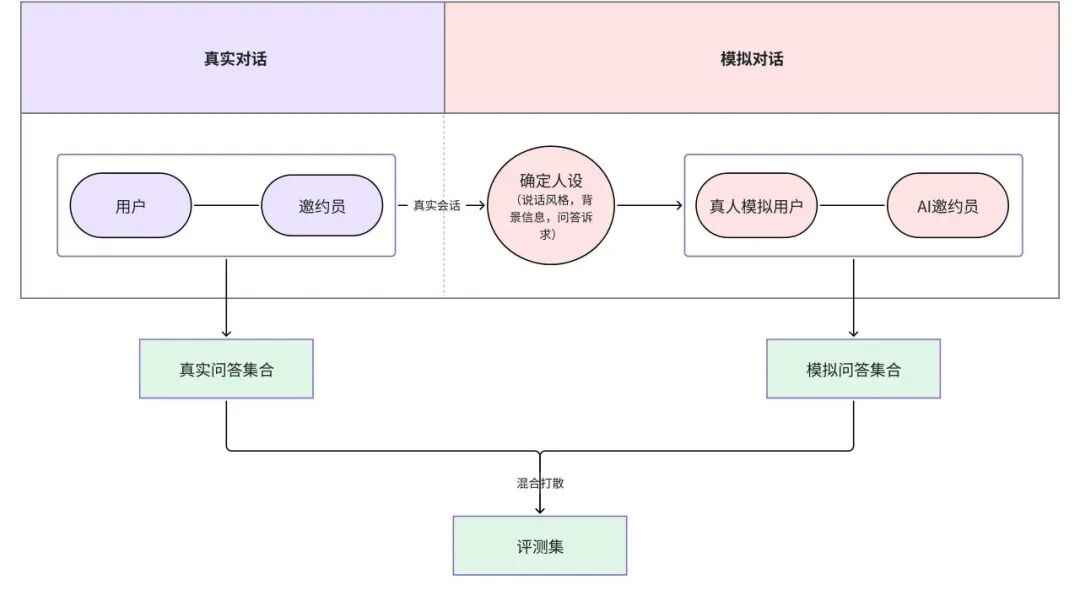
1.2 模拟人设策略
- 策略:模拟人员理解用户诉求,模仿用户的表达方式来进行模拟对话,人设举例:
| 原始对话 | 策略 (理解用户诉求,模仿用户) |
|---|---|
| 邀约员: 朱师傅,我是宜春市货拉拉的,看您这边在平台登记过资料,是有厢式货车想拉货嘛? 司机: 有是有。 邀约员: 是这样的,师傅,确实需要到门店来激活账号,不过这个过程很快,大概也就四十分钟左右,而且激活之后您就可以马上开始接单赚钱了。 司机: 你那个门店在哪?你先告诉我门店在哪里。 邀约员: 咱们宜春这边有两个门店,您现在是在樟树市吗,我帮您推荐离您最近、停车最方便的门店。 司机: 可能要年后,那就年后。我我年前没有时间去搞啊。 邀约员: 理解您的情况,不过年前这段时间订单量特别大,您如果能抽时间过来,真的能多赚不少。今天来激活账号还有个四百块的加油优惠券可以领,名额不多了,您看今天下午有没有时间过来呢? -司机: 嗯,好的好的好的好。 邀约员: 那您看今天下午有没有时间过来呢?今天下午三点半或者四点半,这两个时间点都挺方便的,您看可以吗? -司机: 好的好,那就。 邀约员: 那我先给您登记宜春市高安市中汽大道森泽国际汽贸城二期这个门店,今天下午四点半到店,没问题吧?如果可以的话,那我现在帮您预约,您等我操作下哈。预约成功后会给您发个短信,短信里会有您预约的门店地址和预约时间,您记得看一下短信哈。 -司机: 知道了。 邀约员: 我已经给您预约好了哈师傅。您到时候开着您这辆车,带上身份证、驾驶证、行驶证,直接来门店就行了,师傅您还有其他问题吗? 司机: 好的好的好的,我知道这个要要有啊有啊这个有啊。 邀约员: 后续会有负责司机和订单的同事联系您,或者加您的企业微信,您注意接收哈,咱们门店见,师傅再见。 |
人设:- <strong>背景信息</strong>:当前刚通过审核还未来门店激活 - <strong>问答诉求</strong>:想知道自己的车型能否加入货拉拉 - <strong>说话风格</strong>:积极对话,耐心 - <strong>对话回合次数</strong>:4次 对话举例: AI邀约员: 师傅您好,我这边是济南市货拉拉的,看到您在平台有信息更新,咱们是有考虑接单送货对吗? - 模拟用户:那个那个那个那个3米8箱货能跑吗? - AI邀约员:咱们平台是可以的。建议您带上行驶证、驾驶证,先过来门店看一下,确保符合要求。 - 模拟用户:必须要来门店吗? - AI邀约员:您第一次激活账户必须要来门店的哈,主要是教你接单技巧和APP的使用,咱工作人员会帮您把账号都设置好,后续就不用来门店了。 - 模拟用户:你你过会给我联系吧,我这会开车呢。 - AI邀约员:好的师傅,您专心开车,安全第一。您的账号已经注册好了,下一步就是到线下门店激活账号,我待会把门店预约短信发送给您,您按照短信预约到店激活完就能接单赚钱了,后续也会有负责司机和订单的同事联系您,或者加您的企业微信,您注意接收,再见。 |
2. 评测指标体系
| 指标类型 | 一级指标 | 二级指标 | 指标计算口径 |
|---|---|---|---|
| 核心指标 | 语音回答流畅度 | 回答不流畅会话数/评测会话数 | |
| 合规性-红线触及率 (安全、舆情、声誉风险) |
|||
| 会话准确率 | 准确的会话数 / 评测会话数 | ||
| 会话准确率 | 事实性回答准确率(有标准答案) | 回答准确的会话数/事实性会话数 | |
| 引导回答率 | 符合逻辑的引导回答/引导性会话数 | ||
| 身份完成率(0/1)(业务完成视角) | 有开场白的会话数量/评测会话数 | ||
| 任务完成率(0/1)(业务完成视角) | 成功完成邀约任务的会话数/评测会话数 | ||
| 引导话术得分 |
3. 评测执行流程

评测执行全流程
(二) 评测效果
以某个x版本迭代为例
- 会话能力:优化后的模型“会话能力提升了2p.p(93%—>95%) ,但红线触及率出现了上升2p.p(0%->2%)
- 主流程遵循:优化后的模型提升了4p.p(95%–>99%) ,推测是数据质量提升,模型语义理解能力增强
| 类型 | 指标 | 基线模型 | 指标结果值 |
|---|---|---|---|
| 优化前 | 优化后 | ||
| 合规性 | 红线触及率 | 0% | 0.00% |
| 会话效果 | 会话准确率 | 93% | 93.0% |
| - 事实回答准确率 | 99% | 98.0% | 99% |
| - 引导回答率 | 94% | 95.0% | 96% |
| 主流程遵循 | 主流程遵循准确率 | 98% | 95.0% |
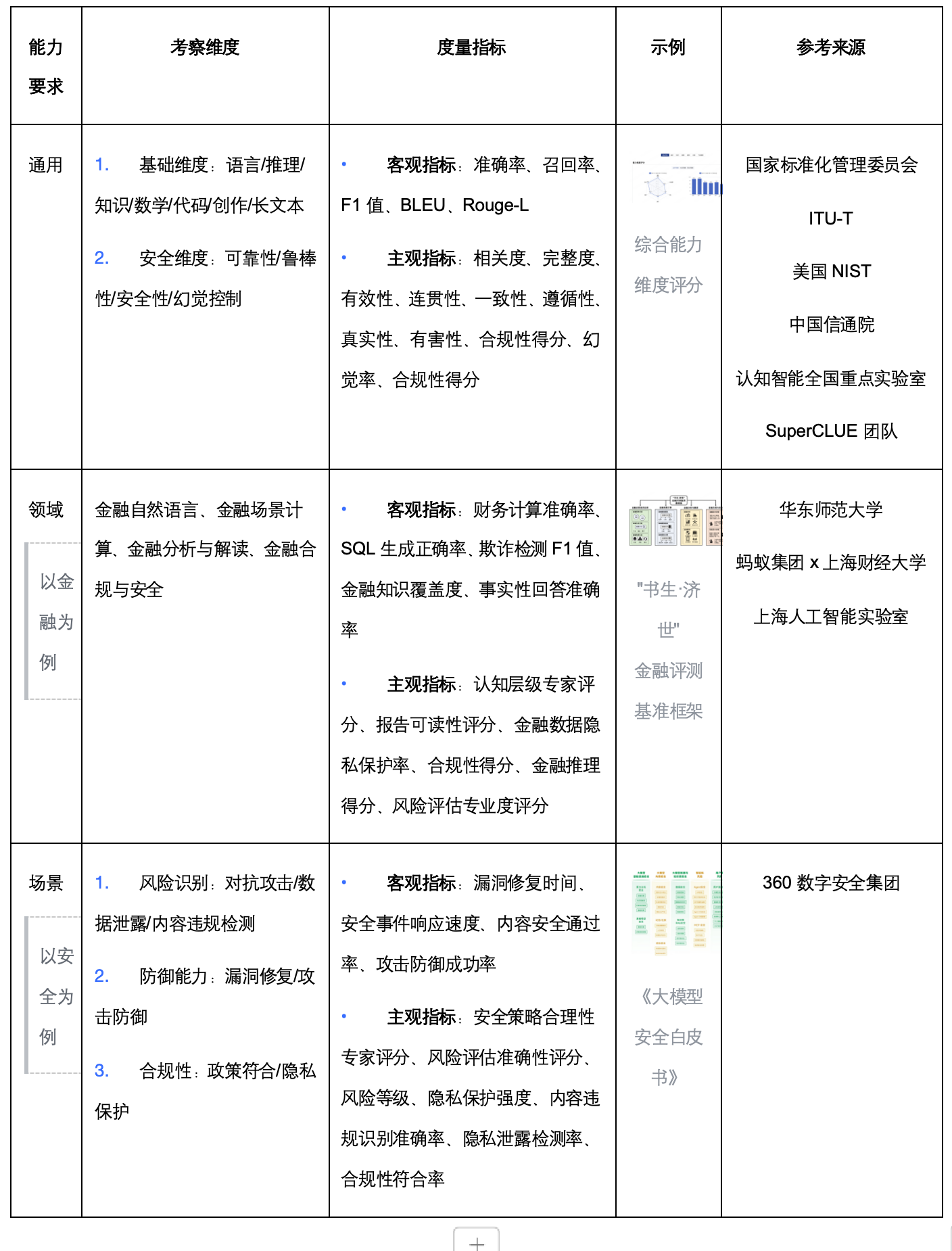
五、附录
国家标准委:GB/T 45288.2-2025人工智能 大模型 第2部分:评测指标与方法-https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcno\=96F5EFDEB471C204455462EAF0C235E6
国际电信联盟电信标准分局(ITU-T):ITU-T F.748.44 基础模型的评估标准:基准测试-https://www.itu.int/rec/T-REC-F.748.44-202503-I
美国国家标准与技术研究院(NIST): 人工智能测试、评估、验证与确认(TEVV)标准零草案大纲-https://www.nist.gov/system/files/documents/2025/07/15/Outline\_%20Proposed%20Zero%20Draft%20for%20a%20Standard%20on%20AI%20TEVV-for-web.pdf
中国信通院:
- “可信AI”评测体系-https://mp.weixin.qq.com/s/H1S3rW-0OU2vZHxxXDkadA
- “方升” 基准测试体系3.0-https://mp.weixin.qq.com/s/V-luVYaaJaozV-tCEIMjIQ
认知智能全国重点实验室:通用大模型评测体系 2.0-https://mp.weixin.qq.com/s/N4GjUef13EPy3qwwDsdljg
SuperCLUE团队:SuperCLUE中文大模型基准测评框架-https://mp.weixin.qq.com/s/9-lVuQENOZYgeH3KooP6kw
华东师范大学:金融数据分析领域框架/FinDABench基准-https://aclanthology.org/2025.coling-main.48/
蚂蚁集团x上海财经大学:金融大模型测评框架/FinEval-KR基准-https://aclanthology.org/2025.finnlp-2.5/
360数字安全集团:《大模型安全白皮书》-https://mp.weixin.qq.com/s/jBeJ4nBRvbrGGMULoSdY2w
